

この記事は10部構成の一部です。
- Reduce Complexity with Production-Grade Kubernetes(英語)
- 高度なトラフィック管理でKubernetesの耐障害性を向上させる方法
- Kubernetesの可視性を向上させる方法(この記事です)
- トラフィック管理ツールを使ってKubernetesを安全にする6つの方法
- Ingressコントローラーの選択ガイド, Part 1: 要件の特定
- Ingress Controllerの選択ガイド, Part 2 : リスクと将来性
- Ingress Controllerの選び方ガイド, Part 3:オープンソース / デフォルト / 商用版
- Ingress Controllerの選択ガイド, Part 4 : NGINX Ingress Controllerのオプション
- サービスメッシュの選び方
- Performance Testing NGINX Ingress Controllers in a Dynamic Kubernetes Cloud Environment(英語)
これらのブログ一式を無料のebookとして下記よりダウンロードいただけます。– Kubernetes のテスト環境から本番環境への移行
マイクロサービスの導入によりデジタル体験を促進する一方で、マイクロサービスアーキテクチャーによってこれらの体験自身を毀損してしまう場合もあります。開発者が新しいアプリケーションを市場に出すために急いで仕事を進めていたとしても、アーキテクチャーのせいで、故障やセキュリティの問題が発生したり、非効率なトラブルシューティングや本来であれば回避可能であった問題の対処が必要となり、時間を浪費するリスクが高まる可能性があります。プロダクショングレードについて取り扱うブログの2つ目では、トラフィックを可視化するコンポーネントによって、どのようにマイクロサービス環境の複雑さを軽減し、セキュリティを向上させることができるのかについて詳しく見ていきます。
可視化することでインサイトを得る
最初に、いくつかの用語の定義について見てみましょう。
- 可視性 – 見ることができる、もしくは見える状態
- インサイト – 人や物について深く理解すること
StackRoxが実施した2020年に調査では、75%のKubernetesユーザーが可視化の機能が必須であるとしました。デプロイされたものを知ることは難しくなる場合があるため、可視化が重要というのはもっともなことです。しかしその一方で、F5が実施した「アプリケーション戦略の現状」調査では、大量のデータを有してはいるものの、インフラストラクチャーとビジネスを保護し、進化させるのに必要なアプリケーションのパフォーマンス、セキュリティ、可用性についてのインサイトが不足しているとの回答が95%を占めていました。では、インサイトはなぜ重要であり、どうすれば獲得することができるのでしょう?
インサイトを用いてできること
- 脆弱性や考えられる攻撃の振る舞いや詳細を検出することで、セキュリティとコンプライアンスを強化
- 顧客より先に問題を発見することで、故障やダウンタイムを削減
- アプリケーションの問題の根本原因を見つけることで、トラブルシューティングを効率化
- トラフィックが望みどおりの場所に転送されていることを確認
- Kubernetes環境で具体的に何が実行され、それが適切に設定・保護されていることを把握
- 遅延やパフォーマンスの履歴に基づき、適量のリソースが使われているのかどうかを確認
- 過去のトラフィックパターンに基づき、状況ごとのニーズを予測
- SLAと比較してパフォーマンスを追跡し、問題がユーザーエクスペリエンスに影響を与える前に早期の警告システムとして機能させるために、レスポンスタイムを計測
インサイトを得るには、リアルタイムと履歴という2種類の可視化されたデータが必要です。リアルタイムのデータは今現在起きている問題の原因の診断を可能にするのに対し、履歴のデータは何が「正常」で、何が「異常」なのかの視点を提供します。可視性についてのこれらの2種類の情報を組み合わせることで、アプリとKubernetesのパフォーマンスに関するきわめて重要なインサイトが得られます。
他のテクノロジー投資と同様に、テクノロジーの恩恵をどうやって享受するのかについての戦略も必要になってきます。F5のレポートからは、雇用や従業員の育成、戦略やプロセス、どのデータをいつ誰が使うのかのコンセンサスに関連する組織的な要因によって、多くの人が貴重なインサイトを得られずにいることがうかがえます。調査結果は以下のような内容となっています。
- 関連するスキルセット – 有能で十分なスキルを持つプロフェッショナルが不足していることはよく知られています。これを裏付ける結果として、必要な人材を見つけられずにいると回答した組織は47%を占めていました。
- データ共有の取り組み – ビジネス上の意思決定者にデータを報告し、ビジネスに影響を与える問題に対し適切に対処するため技術(もしくはその欠如)を認識してもらうためのプロセスと戦略が整備されているとの回答はわずか12%に留まっています。
- 可視化の目的 – ほとんどの回答者がテレメトリーを受動的に(つまり、トラブルシューティングのために)利用しています。これに対して、潜在的なパフォーマンスの低下を監視する目的でデータとインサイトを利用しているとの回答は24%、SLAパフォーマンスの追跡のために利用しているとの回答は16%に留まっています。
この記事の残りの部分は、インサイトの技術的な側面に焦点を当てています。将来の戦略やプロセス、その他の情報についてぜひともご注目ください。
NGINXがどの様に役立つか?
ほとんどのKubernetes環境ですでにモニタリングツールを使用しており、今のところ、もう1つのツールが必要であるということは無いかもしれません。そのため、我々はメトリクスを簡単に外部に公開するためNGINX Plus APIを実装しており、OpenTracing やGrafana、Prometheusなどの人気のあるツールとの統合を提供しています。これにより、あなたはクラスター内のパフォーマンスについて全体を把握することが可能になります。アプリケーションのパフォーマンスと可用性に関する詳細なトレースを取得し、マイクロサービスアプリケーション全体でどのようにリクエストが処理されるかを理解することができます。
-
送受信(North-South)トラフィックに関するインサイト
NGINX Ingress Controllerは、Kubernetesクラスターに出入りするトラフィックについてのインサイトを提供します。NGINXを利用した人気のある3つのIngress Controllerをご存知ですか?すべてがプロダクションレディーなわけではなく、適切でない選択はマイクロサービスの戦略を向上するのではなく複雑にしてしまうこともあるのです。弊社のブログWait, Which NGINX Ingress Controller for Kubernetes Am I Using? は皆様のニーズに最適な選択ができるように選択肢における比較を紹介しております。
- サービスツーサービス(East-West)トラフィックに関するインサイト
NGINX Service Meshは、コンテナ化されたアプリの間を移動するトラフィックについてのインサイトを提供します。
2つの一般的な課題に対しどの様に対処することが可能であるのか、内容を確認し、理解を深めてください:
同テクノロジーが実際に使われている様子を見たいとお考えの場合には、NGINXとGrafanaのエキスパート達によるこちらのライブストリームデモそしてAMA「Ask Me Anything(なんでも聞いてね)のセッションをご覧ください。ロードバランシングとパフォーマンスの主要なメトリクスに関するライブモニタリングを行い、それらのメトリクスをPrometheusにエクスポートし、蓄積されたデータからパフォーマンスを確認できるGrafanaダッシュボードを生成する方法について紹介しています。

課題:アプリケーションが遅い(もしくはダウンしている)
DDoS攻撃かもしれない、あるいはユーザーからWebサイトのエラーが報告されているといったことはないですか? 問題の所在がはっきりするまで解決に取り掛かることはできません。
-
NGINX Ingress Controllerによるライブモニタリング
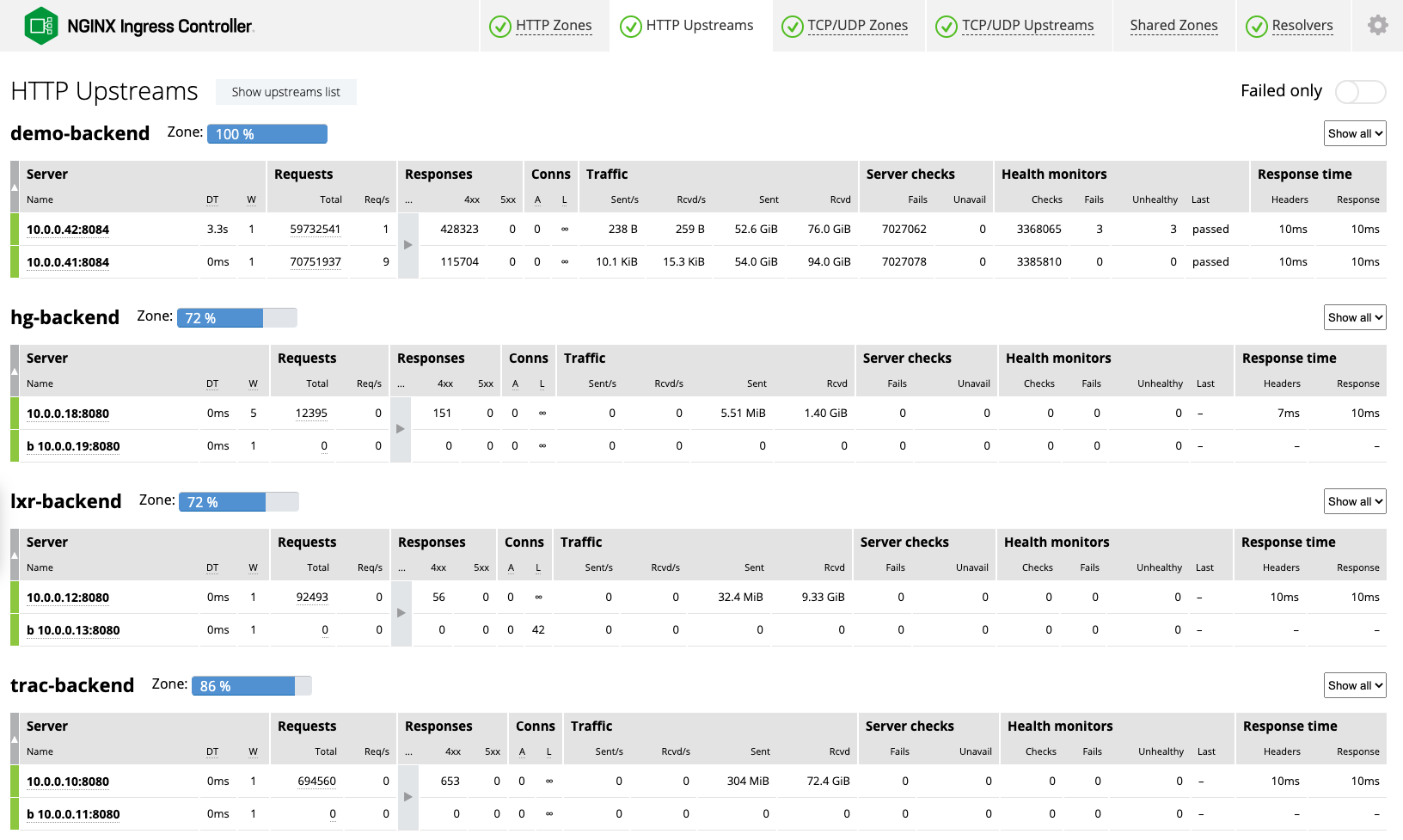
NGINX Plusでは、ライブアクティビティモニタリングダッシュボード(NGINX Plus APIで動作)に、負荷とパフォーマンスに関する数百の主要となるメトリクスが表示されます。1つのPodにいたるまで細かく把握することで、アプリケーションの応答にかかる時間をすばやく簡単に測定し、問題の原因を診断することができます。Kubernetes環境が拡大する際、NGINX Ingress Controllerインスタンスが追加されると、自動でダッシュボードが生成されます。たとえば、HTTP Upstreamsタブの2つのカラムにより、アプリケーションとインフラストラクチャーの状態を瞬時に読み取ることが可能です。
- リクエスト – 任意のアプリケーションで1秒あたりの要求数(Req/s)が標準を下回っている(40が標準の場合に、1秒あたり5要求になるなど)場合、NGINX Ingress Controllerもしくはアプリケーションの設定が間違っている可能性があります。
- レスポンスタイム – レスポンスタイムが10ミリ秒(ms)以下であれば順調ということになります。30~40msを上回る遅延は、アップストリームアプリケーションに異変が生じていることを示すものです。
- NGINX Ingress Controller の スタブステータス
NGINX Open Sourceを使った NGINX Ingress Controllerの場合、NGINX Ingress Controllerに8つの基本的なメトリクスを表示するステータスページが含まれます。 - NGINX Service MeshによるOpenTracing
NGINX Service Meshは、NGINX OpenTracingモジュールによるOpenTracingをサポートしています。本稿の執筆時点で、同モジュールはDatadog、LightStep、Jaeger、Zipkinに対応しています。
課題:クラスターやプラットフォームのリソースが不足している
HTTPエラーが発生した場合、503エラーと40xエラーはあなたがデプロイしたリソースに問題があることを示し、502エラーは設定の変更が動作しないことを意味します。リソースが残り少なくなっている箇所を診断するには、履歴データを使ってください。
- NGINX Ingress Controllerによるロギング
ネットワークの問題を診断する際には、最初にNGINX Ingress Controllerのログをチェックすることで、すべてのログエントリーから関連するKubernetesサービスを特定できるようになっています。エラーに関するログで、関連するサービスを特定します。ログには、タイムスタンプ、送信元IPアドレス、レスポンスステータスコードなど、NGINX Ingress Controller経由で到着したすべてのトラフィックの詳細情報が含まれます。Datadog、Grafana、Splunkなど、人気のアグリゲーターにログをエクスポートすることも可能です。 -
Prometheusメトリクス
特に人気の高いNGINX Ingress Controllerの機能の1つが、拡大を続けるPrometheusのメトリクスのリストです。これには、ネットワークパフォーマンスとIngress Controllerトラフィックに関する指標が含まれます。NGINX PlusベースのNGINX Ingress Controllerは、NGINXのワーカーノードに割り当てられた共有メモリに記録される、コネクション、キャッシング、HTTPおよびTCP/UDPトラフィックに関するメトリクスや、バックエンドサーバによって処理されるHTTPおよびTCP/UDPトラフィックに関するメトリクスなど、その他多くのメトリクスをエクスポートすることが可能です。NGINX Service Mesh はPrometheusサーバーをデプロイし、NGINX Plus APIを使って、NGINX Service MeshのサイドカーおよびNGINX Ingress ControllerのPodからメトリクスを取得します。既存のPrometheusを利用する場合、Prometheusのスクレイプに関する設定が含まれており、Prometheus設定ファイルで取得するメトリクスをカスタマイズすることが可能です。
- Grafanaダッシュボード
NGINX Ingress ControllerとNGINX Service Mesh用に、Prometheus Exporterにより取得するメトリクスを可視化する公式のGrafanaダッシュボードを提供しています。ユーザーは、ミリ秒にいたるまでの詳細な情報、前日比の比較、トラフィックのスパイクなど、詳細なデータを確認できます。たとえば、NGINX Service Meshダッシュボードには、あらゆるサービスやPodのトラフィック量や、監視対象となるアクティブなPodの数が表示され、Podが問題なく稼働していることを知ることができます。
NGINXをプロダクション環境で利用する
NGINX Ingress Controller(NGINX Plusベース)は30日間の無料トライアルが可能で、コンテナ化されたアプリケーションを保護するNGINX App Protectも含まれています。常時無料のNGINX Service Meshは、f5.comからダウンロード可能です。