

ダウンタイムは深刻な結果につながりかねない。
この言葉は医療技術分野の企業にとって他のほとんどの業界よりもより深く響きます。これらの企業の場合、「深刻な結果」には文字通り死も含まれます。私たちは最近ある企業の技術スタックを調査する機会がありました。この企業は医療記録を紙とペンによる手法から世界中いつでも、どこでもアクセスできる安全なデジタルデータへと変革しようとしていました。これらのデータは患者情報から治療指示書、生物学的マーカー、医療分析、履歴記録、そして医療チーム間で共有されるすべてに及びます。
この企業が当初から取り組んでいた問題は一見簡単で「介護士がリアルタイムで簡単にデータを記録できるようにするにはどうすればいいか?」ということでした。しかし、同社が成長するにつれ規模の拡張と常時利用可能なデータを求める必要性からこの問題の解決はますます複雑になっていきました。ここではこの企業が技術的な取り組みの中でどのようにしてKubernetesとNGINX Ingress Controllerを採用するに至ったかを説明します。
技術スタックの一覧
- OS – Linux
- コンテナオーケストレーション – Microsoft Azure Kubernetes Service
- ネットワーキング – Kubernetes, NGINX PlusベースのNGINX Ingress Controller
- ソフトウェア開発言語/フレームワーク – .Net
- 監視、可観測性、アラート – Prometheus
- 監視ダッシュボード – Grafana
- ロギング – Grafana Loki
- データベース – Azure SQL Service
- アプリケーションサーバー – Azure App Service, .Net
- メッセージングとストリーミング – Azure Event Hubs
- キャッシュ – Redis
- セキュリティ – NGINX App Protect
- ロケーションとインフラストラクチャ – 2つのアベイラビリティゾーン、2つのKubernetesクラスタ、15~20ノード、60~100ポッド
- DevOps – Azure DevOps Services
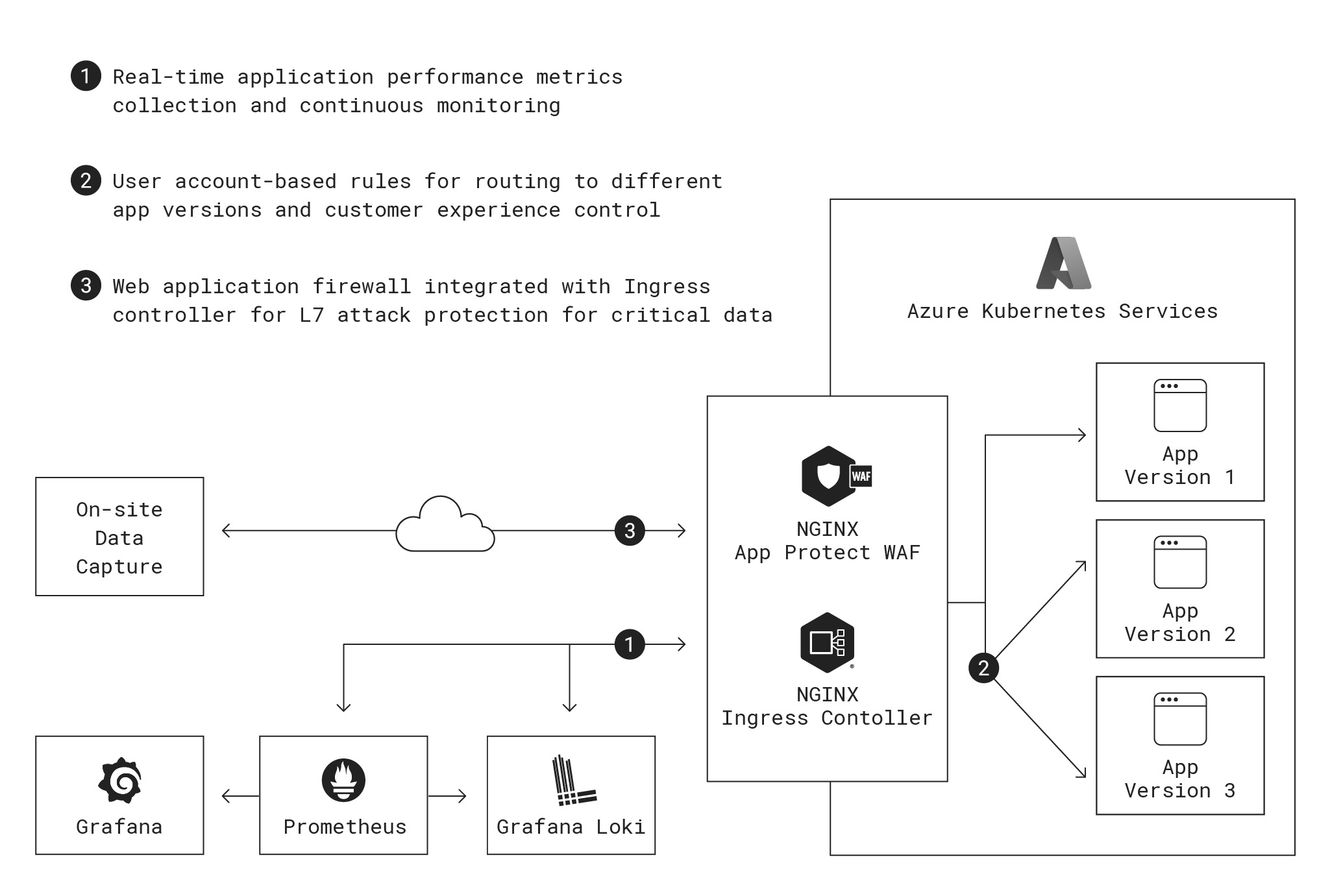
次に、これらのアーキテクチャにおけるNGINXの役割を示します。
紙による医療記録の問題
患者の状態やケアの情報を定期的に取得することは医療従事者にとって重要な任務です。これまで、患者情報の記録は紙または最近ではラップトップやタブレットで行っていました。この方法には以下のようないくつかの重大な欠点があります。
- 医療従事者は1日に何十人もの患者に対応する可能性があり、ケアを提供しながら詳細に情報を記録することは通常は現実的ではありません。その結果、医療従事者が情報を記録するのはシフトの最後になり、その頃には精神的および肉体的な疲労から記録する情報は包括的なものになりがちです。
- また、患者の行動に関する詳細についても自身の記憶に頼らざるを得ません。一貫して正確に記録されていればより大きな健康問題の診断につながった傾向が記録が不正確なことで隠れてしまうかもしれません。
- 紙に記録された情報は救急救命士、緊急治療室のスタッフ、保険会社などの他の組織との共有はもちろん、1つの部署内の部門間でも簡単に共有することはできません。この状況は中央データストアやクラウドに接続されていない場合、ラップトップやタブレットではそれほど改善しません。
これらの課題に対処するため、この企業は簡単に患者情報にアクセスしたり、投薬などの一般的な出来事を記録したりできる簡素化されたデータ記録システムを開発しました。この簡単にアクセスして操作できるシステムにより患者とのやり取りをリアルタイムで記録することが可能になりました。
すべてのデータは同社が管理するクラウドシステムに保存されます。アプリは他の電子医療記録システムと統合され、関係者の行動に関する包括的かつ長期的な情報を提供します。これは介護士がケアの連続性を向上させて安全な履歴記録を作成できるようサポートし、他のヘルスケアソフトウェアシステムと簡単に共有できます。
医師やその他の専門家もこのプラットフォームを患者の受け入れやその他の対応に利用しています。患者の嗜好や個人的なニーズの記録はどの施設でも患者とともにあります。これらの記録は患者が新しい環境で快適に過ごせるよう手助けするために利用でき、その結果、回復時間などの成果向上につながります。
企業が患者データを保存しなければならない期間については厳格な法的要件があります。この企業の開発者は一般的なクラウドアプリケーションよりもはるかに優れたアップタイムSLAを提供する極めて高い可用性のソフトウェアを構築しました。患者のファイルが読み込まれないために救急車を待たせるということはありません。
ガレージからクラウド、そしてKubernetesへ
多くのスタートアップ企業と同様、この企業も当初は共同創業者の自宅のサーバーで最初のPoCを実施することでコストを節約していました。このアイデアに持続性があることが明らかになるとデータセンターでハードウェアを管理するのではなくクラウドにインフラを移行しました。MicrosoftショップであることからAzureを選択しました。初期のアーキテクチャでは、MicrosoftのIIS Webサーバーを実行するマネージドアプリケーションデリバリサービスであるAzure App Serviceの従来の仮想マシン(VM)上でアプリケーションを稼働していました。データの保存と検索にはマネージドアプリケーションとしてVM上で稼働するMicrosoftのSQL Serverを使用することにしました。
クラウドで数年間運用した後、この企業は急速に成長し、拡張の問題に直面しました。無限に拡張する必要があり、さらに、VMでは導入スピードが遅く、またコストもかかるため、水平方向ではなく、垂直方向に拡張する必要がありました。この要件から可能なソリューションとして自然に浮かんだのはコンテナ化とKubernetesでした。コンテナ化が望まれたさらなるポイントは同社の開発者がサービス停止のリスクを負うことなく、アプリケーションとインフラのアップデートを頻繁に提供する必要があるということでした。複数のタイムゾーンにまたがり患者情報が常に追加される中、本番環境に変更を適用するときにダウンタイムはなく、異常によって顧客がすぐに影響を受けるリスクはありません。
同社にとっての論理的出発点はMicrosoftのマネージドKubernetesサービスであるAzure Kubernetes Services(AKS)でした。同社のチームはKubernetesのベストプラクティスを研究しました。その結果、AKS上のノードやポッドで稼働しているトラフィックやアプリケーションを効果的に管理するためにはKubernetesクラスタの前段にIngress controllerが必要であることがわかりました。
トラフィックルーティングは柔軟かつ正確でなければならない
同社のチームはAKSのデフォルトのイングレスコントローラーをテストしましたがそのトラフィックルーティング機能では必要な方法で同社の顧客にアップデートを提供できないことがわかりました。患者ケアに関しては曖昧さや矛盾する情報は許されません。例えば、同じ事象に対してあるケアワーカーにはオレンジフラグ、別のケアワーカーにはレッドフラグが示されることは許されません。そのため、組織内のすべてのユーザーが同じバージョンのアプリを使用する必要があります。これはアップグレードに関する大きな課題です。顧客を新しいバージョンに移行させる自然なタイミングはないので同社はサーバーおよびネットワークレベルでルールを使用して、異なる顧客を異なるアプリのバージョンにルーティングする方法を必要としていました。
これを実現するために、同社は組織内のすべてのユーザーに対して同じバックエンドプラットフォームを実行し、組織内のインフラレイヤーでのセグメント化によるマルチテナンシーは提供していません。Kubernetesでは詳細なトラフィックルールとともに仮想ネットワークルートやブラウザ上のCookieを使ってトラフィックを分割できます。しかし、同社の技術チームはAKSのデフォルトのイングレスコントローラーでは必要に応じて顧客組織レベルや個々のユーザーレベルで運用するルールを使用しない場合、パーセンテージベースのみでしかトラフィックを分割できないことに気づきました。
その基本的な構成ではNGINX Open SourceベースのNGINX Ingress Controllerにも同様の制限があるので、同社はきめ細かいトラフィック制御をサポートするエンタープライズグレードの製品であるNGINX PlusベースのNGINX Ingress Controllerに移行することにしました。NGINX Ingress Controllerはその高いレベルの柔軟性と制御によりMicrosoftやKubernetesコミュニティから推奨されていたのでこの選択は確固たるものとなりました。この構成は、(従来のトラフィック管理とは対照的に)ポッド管理に対する同社のニーズをより効果的にサポートし、ポッドが適切なゾーンで実行され、トラフィックがそれらのサービスにルーティングされることを保証します。トラフィックが内部的にルーティングされることもありますがほとんどのユースケースでは可観測性の理由からNGINX Ingress Controllerを介してルーティングバックされます。
潜在的な問題:監視、可観測性、アプリケーションパフォーマンス
NGINX Ingress Controllerにより技術チームはデベロッパーおよびエンドユーザーエクスペリエンスを完全に制御しています。ユーザーはログインしてセッションを確立するとすぐに新しいバージョンにルーティングされるか、古いバージョンに戻されます。パッチは組織内のすべてのユーザーに同時かつほぼ瞬時に適用できます。このソフトウェアはクラウドプラットフォーム全体でのDNS伝播やネットワーキングのアップデートに依存しません。
NGINX Ingress Controllerはこの企業の要件であるきめ細かい継続的な監視も満たしています。アプリケーションパフォーマンスはヘルスケアにおいて非常に重要です。遅延やダウンタイムは特に生死に関わるような状況では臨床ケアの成功を妨げる可能性があります。Kubernetesに移行した後、同社が気づかなかったダウンタイムが顧客から報告され始めました。同社はすぐに問題の原因を突き止めました。それはAzure App Serviceがサンプリングデータに依存しているということでした。サンプリングは平均値や大まかな傾向には適していますが拒否されたリクエストや不足しているリソースなどは完全に見落としてしまいます。また、介護士がチェックインして患者データを記録することで30分ごとに発生することがよくある使用量の急増も示されません。同社は遅延、エラーの原因、不正リクエスト、利用できないサービスなどを完全には把握できていませんでした。
問題は他にもありました。Azure App Serviceのデフォルトでは保存データの保持期間はわずか1か月であり、多くの国の法律で義務付けられている数十年にははるかに及びません。保持期間を延長するために必要に応じてデータストアを拡張するには法外なコストがかかりました。さらに、AzureソリューションではKubernetesのネットワーキングスタックの内部を見ることができません。NGINX Ingress Controllerはレイヤー4とレイヤー7のトラフィックを処理するため、インフラとアプリケーションの両方のパラメーターを監視できます。
パフォーマンス監視と可観測性については同社はGrafanaの可視化エンジンとダッシュボードに接続されたPrometheusの時系列データベースを選択しました。PrometheusとGrafanaとの統合はNGINXのデータプレーンとコントロールプレーンにあらかじめ組み込まれているので技術チームはわずかな設定変更を行うだけですべてのトラフィックをPrometheusとGrafanaのサーバーを経由させることができました。情報はGrafana Lokiロギングデータベースにルーティングされるのでログの分析が簡単になりソフトウェアチームは長期的にデータ制御を強化できました。
また、この構成はトラブルシューティングやバグ修正のために極めて頻繁かつ大量のデータサンプリングが必要になるインシデントが将来的に発生しても対応できます。このようなタイプのインシデントに対処するにはほとんどの大規模クラウド企業が提供するアプリケーション監視システムではコストがかかるかもしれませんが、Prometheus、Grafana、Lokiによりこのユースケースにかかるコストとオーバーヘッドは最小限で済みます。これら3つはすべて安定したオープンソース製品であり、一般的に必要なことは初期チューニング後にパッチを適用する程度です。
守り続ける:高可用性とセキュリティ
この企業は常に最も機密性の高いデータの1つを保護できるセキュリティとアプリが必要なときにいつでも利用できる高可用性の2つを重視してきました。Kubernetesへの移行において、両方の能力を強化するためにいくつかの変更を行いました。
高可用性を実現するため、技術チームはアクティブ/アクティブ、マルチゾーン、マルチジオの分散インフラストラクチャ設計を導入し、単一障害点のない完全な冗長性を提供しています。チームは2つの異なる地域にあるデュアルKubernetesクラスタでN+2アクティブ/アクティブインフラストラクチャを維持しています。それぞれの地域内でソフトウェアはインフラのどのレイヤーで障害が発生してもカバーできるように複数のデータセンターにまたがりダウンタイムリスクを軽減します。アフィニティと非アフィニティのルールによりユーザーとトラフィックを稼働中のポッドに即座にルーティングしてサービスの中断を防ぎます。
セキュリティに関してチームはWebアプリケーションファイアウォール(WAF)を導入し、不正リクエストや悪意のあるアクターから保護しています。OWASP Top 10に対する保護はほとんどのWAFで提供されている最低限必要な機能です。チームはアプリ作成においてネイティブのAzure WAFやModSecurityなど多くのWAFを調査し、最終的にインラインWAFと分散型サービス拒否(DDoS)保護を備えたNGINX App Protectを選択しました。
NGINX App Protectの大きな利点はNGINX Ingress Controllerとのコロケーションにより冗長性のポイントをなくし遅延を削減できることです。他のWAFはKubernetes環境の外部に配置する必要があり、そのため遅延が生じ、またコストもかかります。わずかな遅延(たとえばリクエストあたり1ミリ秒)であっても、時間が経てば大きくなります。
思いがけない効果:開発者のダウンタイムなし
アプリケーションとネットワーキングのインフラのほとんどをAKSに移行し終え、デベロッパーエクスペリエンス(DevEx)も大幅に改善されました。今では開発者はほぼ必ず、顧客自身が気づく前に問題を特定でき、移行後、エラーに関するサポートコールの量は約80%減少しました。
同社のセキュリティチームとアプリケーションパフォーマンスチームは詳細なGrafanaダッシュボードと統一されたアラート機能を利用することで複数のシステムをチェックしたり、異なるプロセスからの警告テキストや呼び出しのトリガーを実装したりする必要がなくなりました。開発チームとDevOpsチームは非常にきめ細かいブルーグリーンデプロイメントによりコードとインフラのアップデートを毎日でも、1日に複数回でも提供できるようになりました。以前のアップデート提供は週に1、2回の頻度で、使用率が落ち着いた時間帯に行う必要があり厳しい状況でした。現在ではコードは準備ができた時点で提供され、開発者はアプリケーションの動作を観察することで影響を直接監視できます。
その結果、ソフトウェア開発の高速化、開発者の士気の向上、より多くの人命の救助など、あらゆる面で状況が良くなりました。


